Humans as ‘prediction machines’
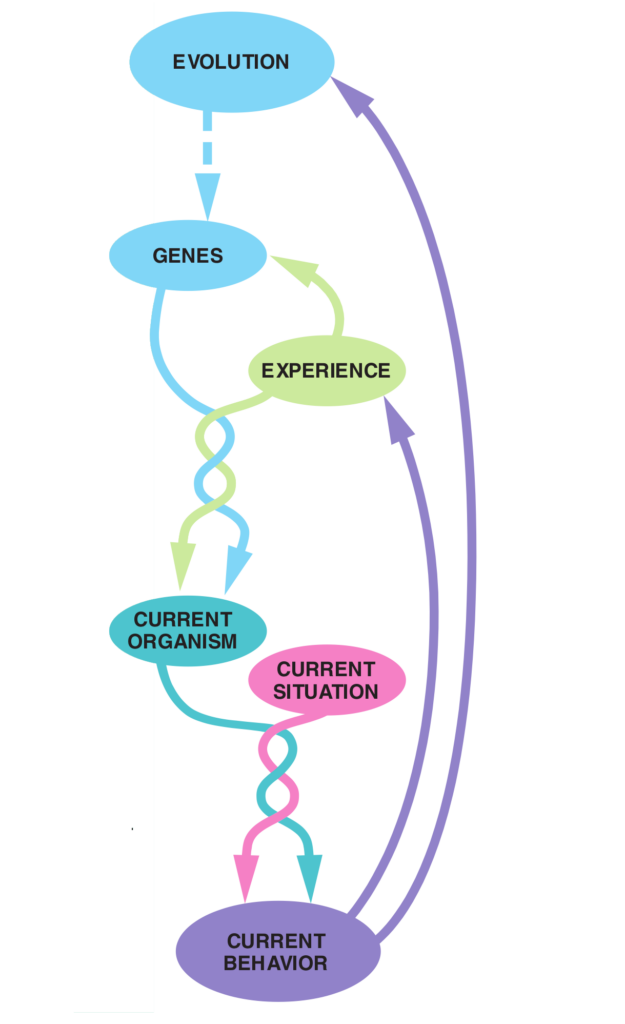
Human beings are essentially ‘prediction machines’. Human beings are always predicting something, consciously or subconsciously. Our brains are wired to constantly analyze patterns and make predictions based on those patterns in order to make sense of the world around us, to prepare for future events and to “autocomplete’ missing bits of information in our view of the world. In that perspective we make predictions for the short as well as for the long term. For acting as well as planning we use a mental model to navigate and guide us through an environment of threats as well as opportunities.
Every human behavior is an investment with an uncertain pay off
The human urge for predicting the future has all to do with optimizing Darwinistic fitness. In order to enhance survival and reproduction value, humans benefit from knowing how the future will look like, so they can anticipate or steer the outcome to their own benefit with their behavior. In that perspective every human behavior is an investment, with a probabilistic pay off in the (distant or not so distant) future.
For example, when we are walking down a busy street, our brain is constantly predicting where people are likely to move and how we need to adjust our own movements to avoid collisions. Similarly, when we hear a car approaching, our brain predicts the direction and speed of the car to help us determine when it’s safe to cross the road. If we are not sure, we make predictions based on heuristics, biases or even superstition. This all to make an ‘educated’ guess and to sum up all ‘apples and oranges’ .

This process of planning of humans and interacting with an environment can be modeled through the paradigm of Reinforcement Learning (RL) which is a special branch in Machine Learning (ML). RL in AI is schematically described below and is based on the idea of trial and error learning. The goal of reinforcement learning is to train an agent to take actions in an environment in order to predict and maximize a cumulative expected reward signal.
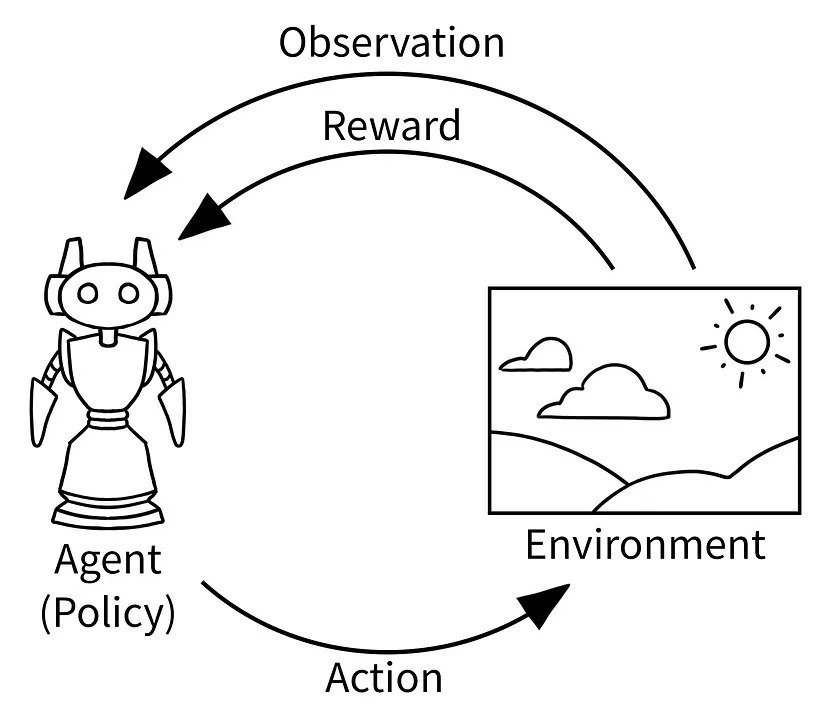
In reinforcement learning, an agent interacts with a possibly uncertain environment by taking actions, and the environment provides feedback to the agent in the form of a reward signal. The reward signal indicates how good or bad the agent’s action was in achieving its objective. The agent’s goal is to learn a policy, which is a mapping from states to actions, that maximizes the cumulative expected reward over time.
The reinforcement learning process can be broken down into three main components: the agent, the environment, and the reward signal. The agent takes actions based on its current perceived state, and the environment responds by transitioning to a new state and providing a possibly uncertain reward signal.