Multi Agent Reinforcement Learning
Multi Agent Reinforcement Learning (MARL) as a tool for modeling human behavior
Descriptive agenda of Multi Agent Reinforcement Learning (MARL): The descriptive agenda uses MARL to study the behaviors of natural agents, such as humans and animals, when learning in a population.This agenda typically begins by proposing a certain MARL algorithm which is designed to mimic how humans or animals adapt their actions based on past interactions. Methods from social sciences and behavioral economics can be used to test how closely a MARL algorithm matches the behavior of a natural agent, such as via controlled experimentation in a laboratory setting. This is then followed by analyzing whether a population of such natural agents converges to a certain kind of equilibrium solution if all agents use the proposed MARL algorithm.
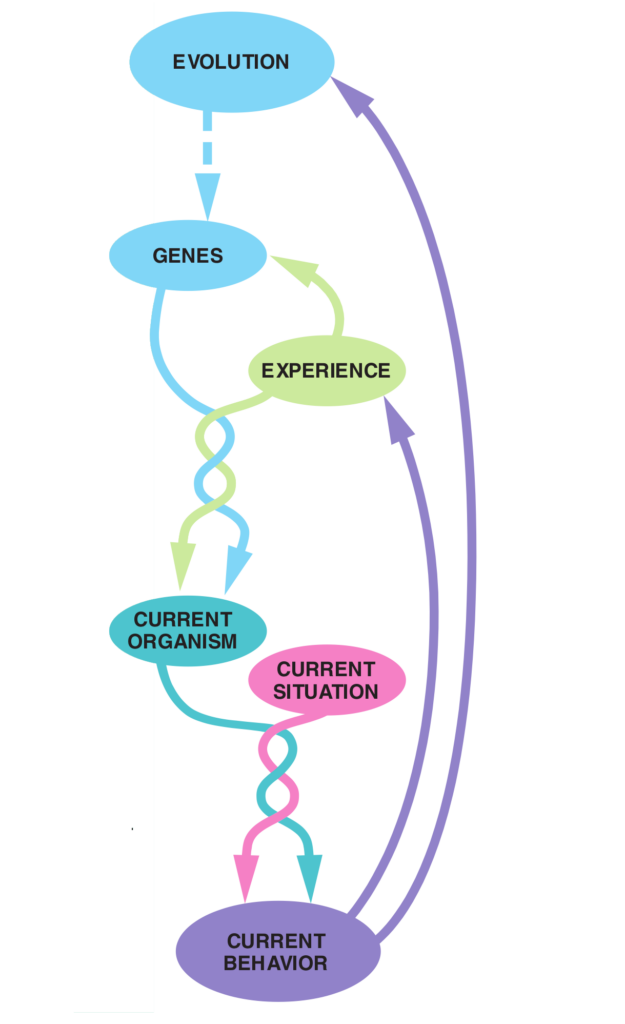
It is in our view very unlikely if evolution started all over again from the big bang, we would come up with the same outcome. Perhaps dinosaurs ruled the world after all, instead of humans, or whatever. Therefore, it is pointless (and most likely also impossible) to simulate and apply reinforcement learning of human behavior by starting from scratch because it will lead to absurdly varying outcomes of human life and human behavior. (if humans would appear at all). Therefor it is necessary to a priori endow characteristics of humans into simulation models, making modeling of course subjective unfortunately. It is nevertheless the challenge to identify emergent behavior out of human group dynamics with multi agent reinforcement learning, with making as few presumptions as possible.
The significance of multi-agent reinforcement learning
Building and observing interactions between artificial agents could help us to gain better understanding about human behavior.
Modeling MARL
Multi agent reinforcement learning (MARL) is an interesting avenue to investigate human behavior and emergent group phenomena. Although recent years have brought advances in this field, significant results are still scarce.
MARL can be sub divided into three categories:
- Cooperative setting
- Competitive setting
- Mixed setting
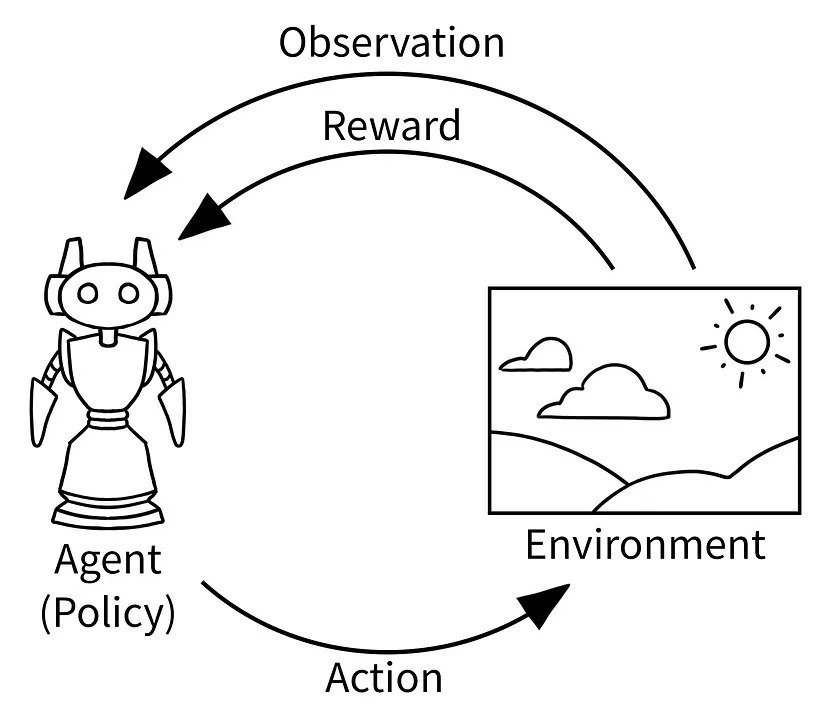
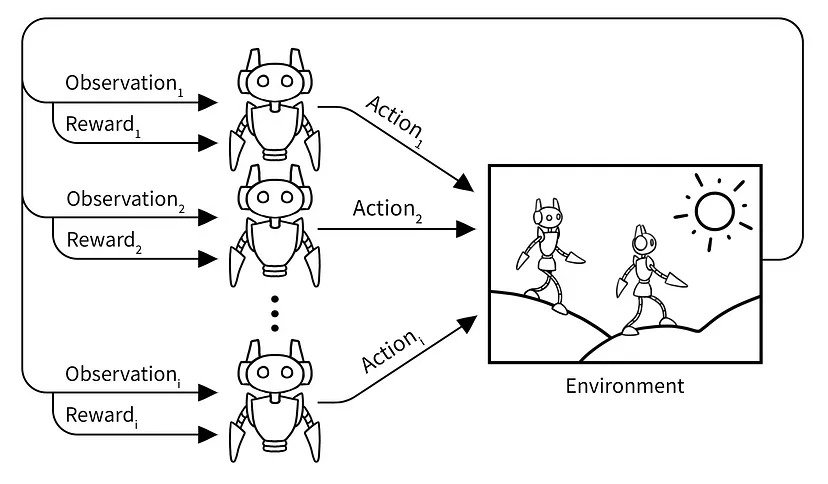
Areas of significance
- The sequence of the agents in a time cycle do matter. Agents can act (partially) simultaneous and/or (partially) sequentially
- Function approximation
- Stochastic gradient descent
- Non-stationary.
- Importance sampling
- Mixed games can probably use the loss aversion model of Kahnemann and Tversky in the reward structure. This sheds likely new light on the zero-sum asymmetric reward intake.
- Neural networks to solve for reinforcement leaning networks